One-Shot Image-to-Image Translation via Part-Global Learning with a Multi-adversarial
Abstract
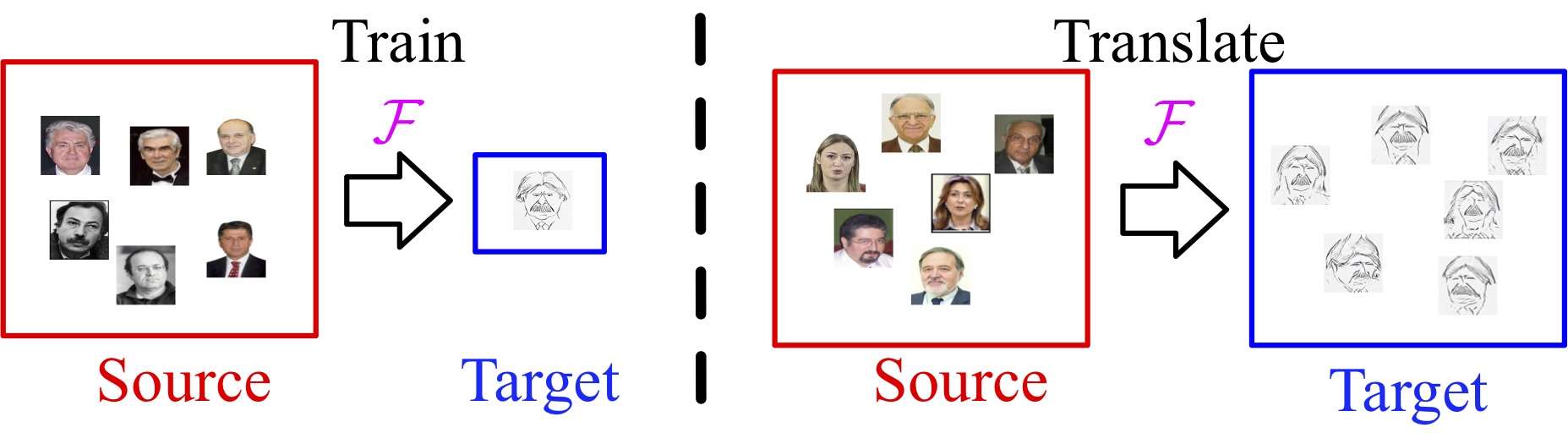
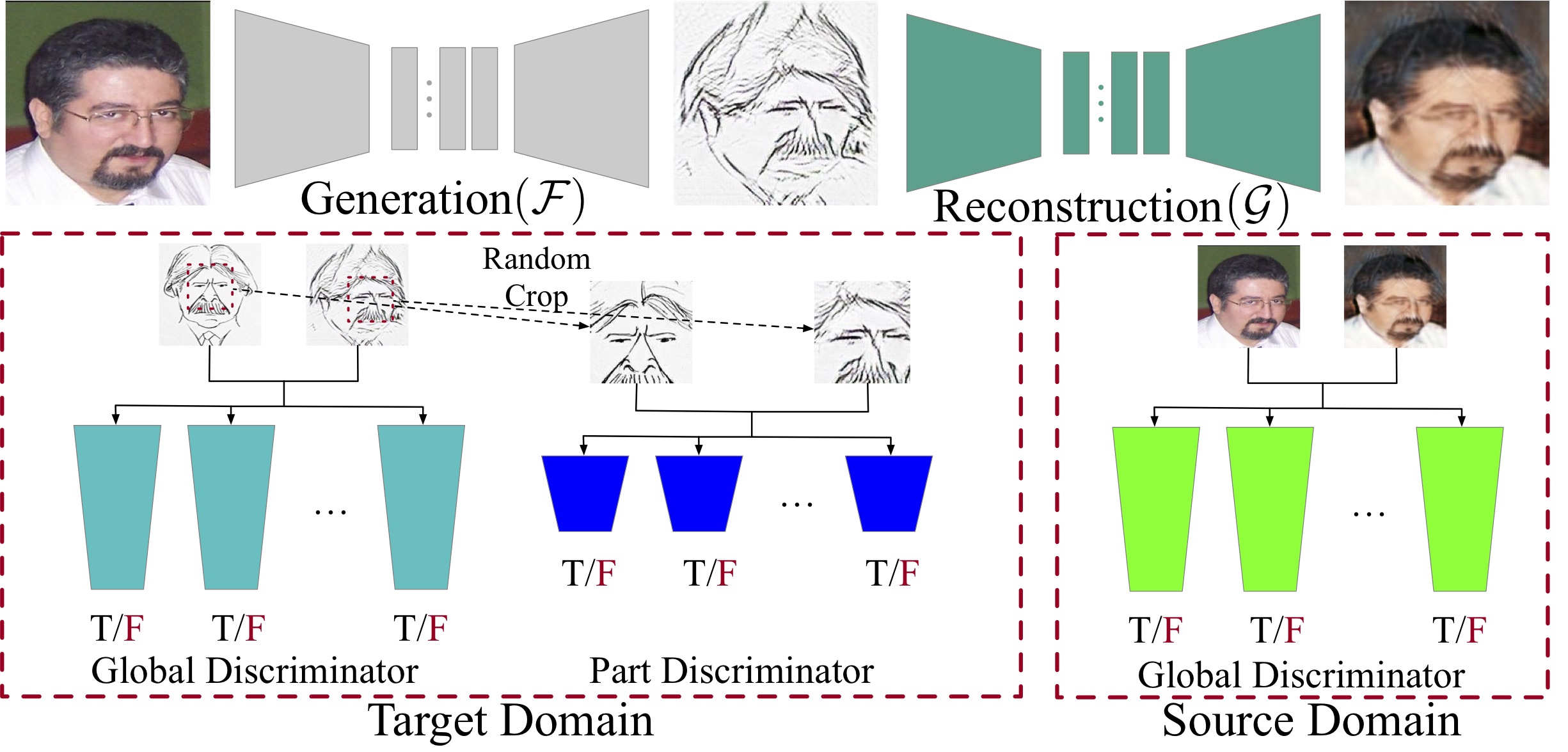
It is well known that humans can learn and recognize objects effectively from several limited image samples. However, learning from just a few images is still a tremendous challenge for existing main-stream deep neural networks. Inspired by analogical reasoning in the human mind, a feasible strategy is to ``translate'' the abundant images of a rich source domain to enrich the relevant yet different target domain with insufficient image data. To achieve this goal, we propose a novel, effective multi-adversarial framework (\textbf{MA}) based on part-global learning, which accomplishes the one-shot cross-domain image-to-image translation. In specific, we first devise a part-global adversarial training scheme to provide an efficient way for feature extraction and prevent discriminators from being overfitted. Then, a multi-adversarial mechanism is employed to enhance the image-to-image translation ability to unearth the high-level semantic representation. Moreover, a balanced adversarial loss function is presented, which aims to balance the training data and stabilize the training process. Extensive experiments demonstrate that the proposed approach can obtain impressive results on various datasets between two extremely imbalanced image domains and outperform state-of-the-art methods on one-shot image-to-image translation.
Architecture
Citation
@article{zheng2021one,
title={One-Shot Image-to-Image Translation via Part-Global Learning with a Multi-adversarial Framework},
author={Zheng, Ziqiang and Yu, Zhibin and Zheng, Haiyong and Yang, Yang and Shen, Heng Tao},
journal={IEEE Transactions on Multimedia},
year={2021},
publisher={IEEE}
}